Spark Modes of Deployment – Cluster mode and Client Mode
While we talk about deployment modes of spark,
it specifies where the driver program will be run, basically, it is
possible in two ways. At first, either on the worker node inside the
cluster, which is also known as Spark cluster mode.
Secondly, on an external client, what we call it as a client spark mode. In this blog, we will learn the whole concept of Apache Spark modes of deployment.
At
first, we will learn brief introduction of deployment modes in spark,
yarn resource manager’s aspect here. Since we mostly use YARN in a
production environment. Hence, we will learn deployment modes in YARN in
detail.
Spark Deploy modes
When
for execution, we submit a spark job to local or on a cluster, the
behaviour of spark job totally depends on one parameter, that is the
“Driver” component. Where “Driver” component of spark job will reside,
it defines the behaviour of spark job.
Basically, there are two
types of “Deploy modes” in spark, such as “Client mode” and “Cluster
mode”. Let’s discuss each in detail.
1. Spark Client Mode
As
we discussed earlier, the behaviour of spark job depends on the
“driver” component. So here,”driver” component of spark job will run on
the machine from which job is submitted. Hence, this spark mode is
basically “client mode”.
- When job submitting machine is
within or near to “spark infrastructure”. Since there is no high network
latency of data movement for final result generation between “spark
infrastructure” and “driver”, then, this mode works very fine.
- When
job submitting machine is very remote to “spark infrastructure”, also
have high network latency. Hence, in that case, this spark mode does not
work in a good manner.
2. Spark Cluster Mode
Similarly,
here “driver” component of spark job will not run on the local machine
from which job is submitted. Hence, this spark mode is basically
“cluster mode”. In addition, here spark job will launch “driver”
component inside the cluster.
- When job submitting machine is
remote from “spark infrastructure”. Since, within “spark
infrastructure”, “driver” component will be running. Thus, it reduces
data movement between job submitting machine and “spark infrastructure”.
In such case, This mode works totally fine.
- While we work with
this spark mode, the chance of network disconnection between “driver”
and “spark infrastructure” reduces. Since they reside in the same
infrastructure. Also, reduces the chance of job failure.
3. Running Spark Applications on YARN
YARN controls resource management, scheduling, and security when we run spark applications on it. It is possible to run an application in any mode here, whether it is cluster mode or client mode.
In
addition, while we run spark on YARN, spark executor runs as a YARN
container. There is a case where MapReduce schedules a container and
starts a JVM for each task. There spark hosts multiple tasks within the
same container. Hence, it enables several orders of magnitude faster
task startup time.
Spark Deploy Modes in YARN
Each
application instance has an ApplicationMaster process, in YARN. That is
generally the first container started for that application. However,
the application is responsible for requesting resources from the
ResourceManager.
As soon as resources are allocated, the
application instructs NodeManagers to start containers on its behalf.
For an active client, ApplicationMasters eliminate the need.
Basically,
the process starting the application can terminate. Also, the
coordination continues from a process managed by YARN running on the
cluster.
1. Cluster Deployment Mode
When
the driver runs in the applicationmaster on a cluster host, which YARN
chooses, that spark mode is a cluster mode. It signifies that process,
which runs in a YARN container, is responsible for various steps.
Such
as driving the application and requesting resources from YARN. Hence,
the client that launches the application need not continue running for
the complete lifespan of the application.
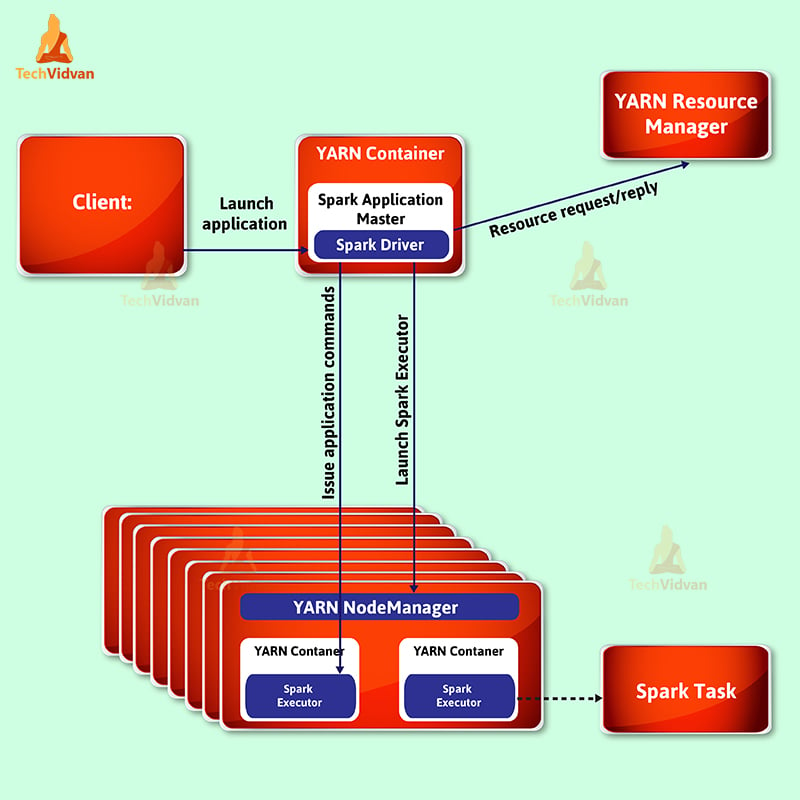
Spark Modes – Cluster Development Mode
Note:
For using spark interactively, cluster mode is not appropriate. Since
applications which require user input need the spark driver to run
inside the client process, for example, spark-shell and pyspark. That
initiates the spark application.
2. Client Deployment Mode
When
the driver runs on the host where the job is submitted, that spark mode
is a client mode. To request executor containers from YARN, the
ApplicationMaster is merely present here. To schedule works the client
communicates with those containers after they start.
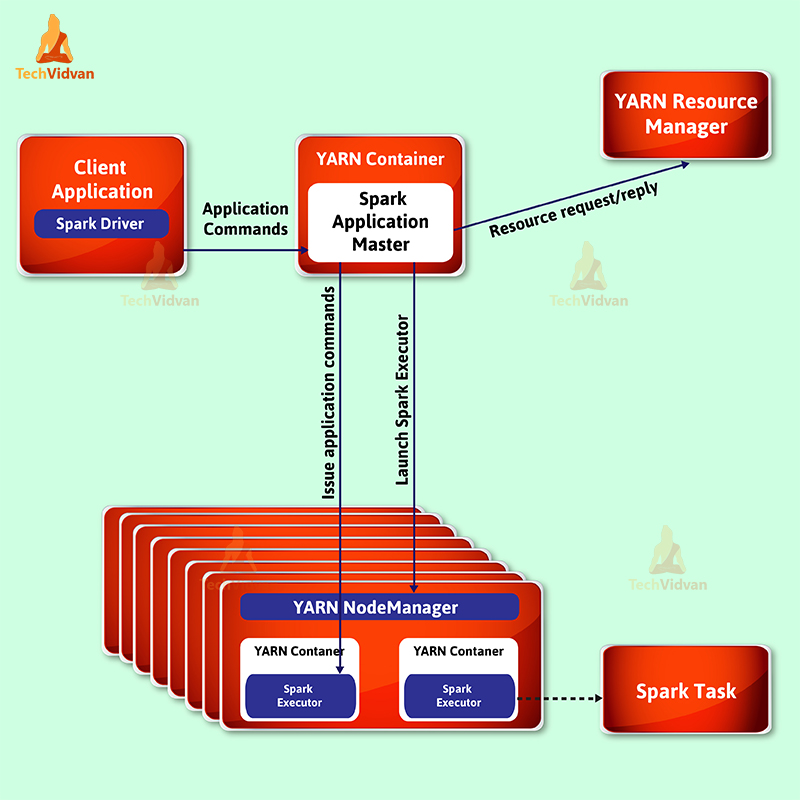
spark modes – client deployment mode



Comments
Post a Comment